
We are seeing advances in browser technologies that have the potential to change the way we write applications on the web. Now that ES6 modules are well on their way to being supported by all evergreen browsers, we may no longer need to build and bundle our JavaScript code using complex and proprietary tooling. Our source code is becoming our distributed code!
TLDR; You can now import JavaScripts directly from your JavaScripts in the browser, at runtime. The benefits of this are amplified by CDN services such as unpkg.
Unpkg was created and is maintained by Michael Jackson from React Training; its sponsors include CloudFlare and Google (via the Angular project). Despite being somewhat under the radar, unpkg is a big deal and serves up more scripts than you would believe!
From April 3 to May 3, 2019 unpkg served 16,811,631,733 requests and a total of 213 TB of data to 1,500,325,458 unique visitors, 99.16% of which were served from the cache. Woah.
While build step free single-page web apps are still on the bleeding edge, these numbers hint at great demand and demonstrate that there is tremendous infrastructure in place to support this approach.
We have been experimenting with this methodology and new tooling for a while now, but wanted to improve the overall developer experience making it easier to work with and generally more welcoming to newcomers.
New problems
When importing a script from the internet (rather than installing it locally with npm or yarn) it is very easy to pull in more than you bargained for. For example one line of code such as:
import lodash from 'https://unpkg.com/lodash-es'
May appear pretty harmless on the surface, but it set in motion a recursive dependency resolution process that runs client-side and that—in this particular case—results in more than 600 files (~600KB) being requested, downloaded, and evaluated by the browser. Yikes!
Truly understanding the impact of your imports is hard. To begin to get an idea of what is going on under the hood you could visit the package url at https://unpkg.com/lodash-es and manually inspect the file.
However, all you are presented with is a file that potentially depends on some other files. You have no idea what those files are doing and if they have dependencies of their own. Nobody reads through their entire node_modules directory, but as responsible developers, we should be aware of the implications of pulling in third-party dependencies, especially when doing it at runtime. Proper tooling can help us here.
We wanted to help in this regard by developing a tool that makes it easier to analyze and understand the code your application depends on.
Introducing runpkg
We took inspiration from tools like Bundlephobia, Octolinker, and Githistory, whilst we asked ourselves: What are the most useful and impactful functionalities we might need in a CDN-driven package/module era?
- Make the published code more readable.
- Make the packages more navigable.
- Make the impact of importing packages more transparent.
That's why we've built runpkg: the online package explorer.
How to runpkg
So, how do you use runpkg? Well, just prefix any unpkg url with r!
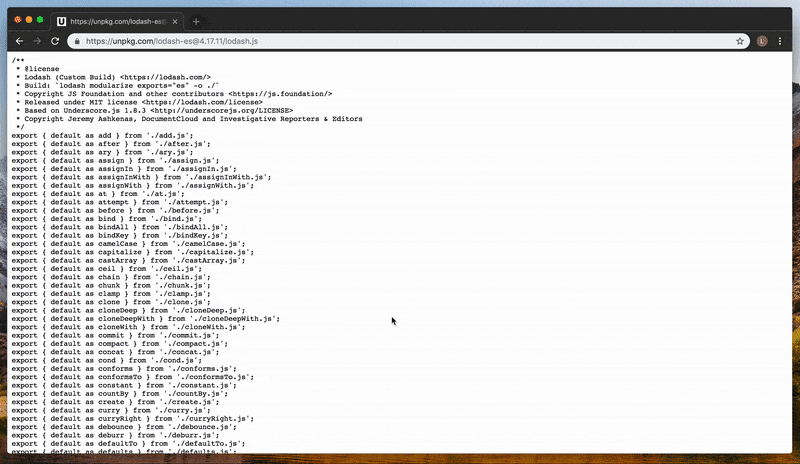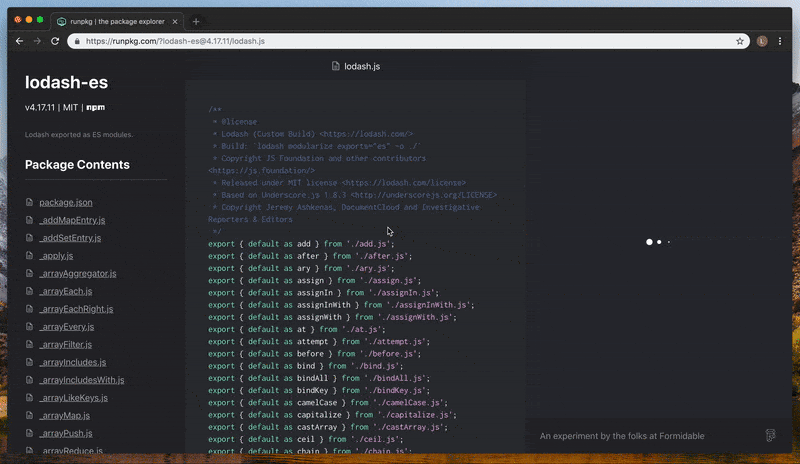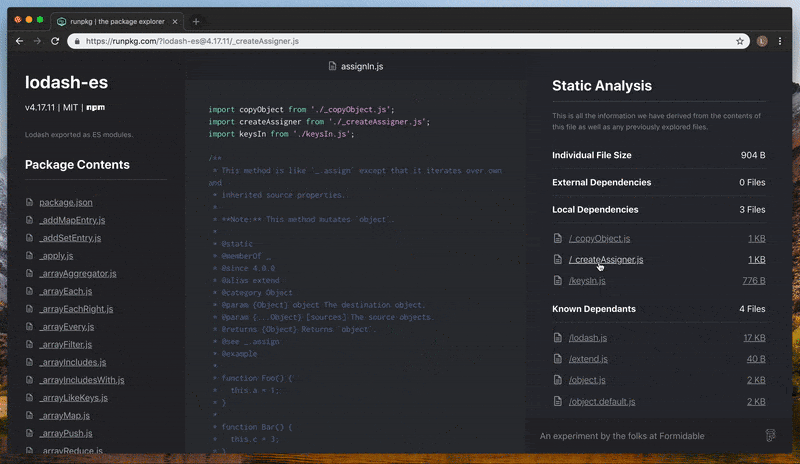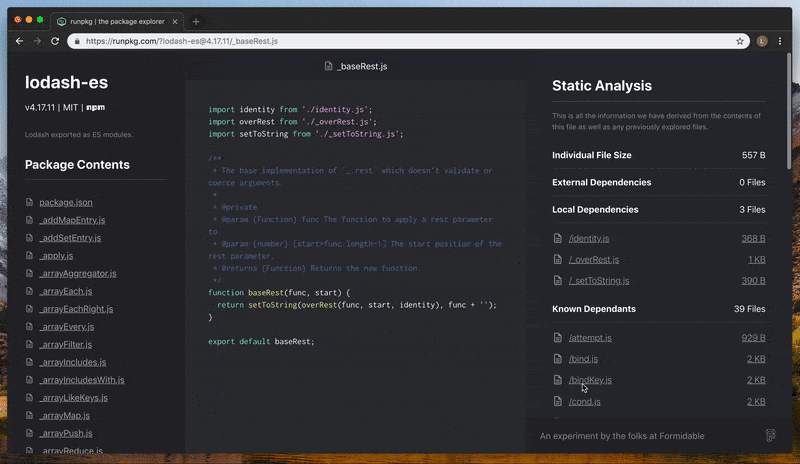
Runpkg turns a static file into an interactive and information-rich browsing experience. In the navigational panel to the left we display package information and directory structure, which enables quick switching between files. Front and center we render a syntax-highlighted representation of the code itself to make it much more human readable. In the background we perform static analysis on the contents of the current file, generating a dependency graph and surfacing insights on the right-hand side panel.
These are the key features we set out to implement, but the fun doesn't stop there. We have a long list of potential improvements including prettier integration, permalinking, version diffing, and more advanced static analysis.
Visit https://runpkg.com to try it out and give us feedback on Twitter!
Disclaimer! Handling all the different module definitions and resolution algorithms employed in the wild (imports, exports, AMD, UMD, CommonJS, ejs, .mjs, require, relative, absolute, external, https urls, the list goes on...) turned out to be an interesting, but tough challenge to solve. If you find an edge case we didn't yet discover, please do let us know! The project is fully open source and contributions in the form of ideas, bug reports, and pull requests are welcome via the GitHub repository!
Runpkg itself has been built using a buildstep-less ES6 module architecture, so check out the source code. You can read more about our experiments with ES modules at https://formidable.com/blog/2019/no-build-step.

